Slackの旧ワークスペースを、その構造を保ったまま別の新ワークスペース(新WS)に移行するのではなく、特定のチャンネルの投稿だけを新WSに移行させたいとき、CSVファイルを使うのが便利だ。WSごと移行よりも、工数が少なく作業が容易である。
slack.com
に解説があるが、実際に作業してみると、ここに書かれていない仕様を理解しなければならなかった。理解した内容をメモとして残す。CSVファイルの作成方法は後日解説する。
次の2条件で移行したいとする。
- 新WSには、移行させたいユーザーが全員参加している
- 移行先のチャンネル種はプライベートチャンネル
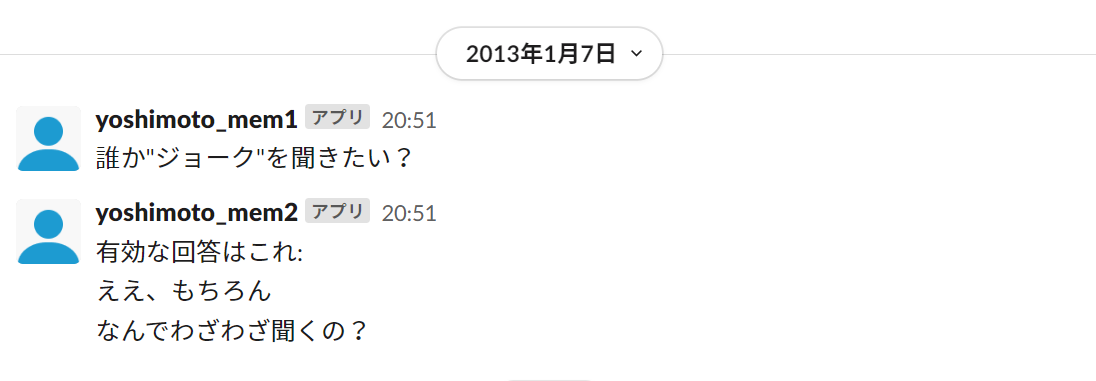
Slackが例示しているCSVファイルは以下の通りである。
"1357559471","random","myles","誰か\"ジョーク\"を聞きたい?"
"1357559472","random","myles","有効な回答はこれ:
ええ、もちろん
なんでわざわざ聞くの?"
Unixtime(詳細は後述)、チャンネル名、投稿者名、投稿内容 の順でカンマ区切りで記述する。それぞれの要素は""で囲む。つまり、"がメタ文字になるので、""内で"を使うときは、例のようにバックスラッシュを付けて\"としなければならない。投稿内容では例のように改行\nを使うことができる。
ユーザーのマッピング
結論を先に言うと、どのような手段を持ってしても(注1)、ユーザーを自動でマッピングすることはできない。Slackに問い合わせたところ、自動的にマッピングされないのは既知の不具合で、修正が行われない可能性がある(私が受けた感触だと、今後修正されることはない)と連絡を受けた(2022/08/01)。CSVファイルに記述したユーザー名は、インポート時に小文字になり、スペースなどは_に置き換わってしまう。そのユーザー名を見ながら、新WSでマッチするユーザーをプルダウンから選ぶ。プルダウンに表示されるのは、displaynameなので、CSVファイルのユーザー名はdisplaynameにしておくと分かりやすいだろう。
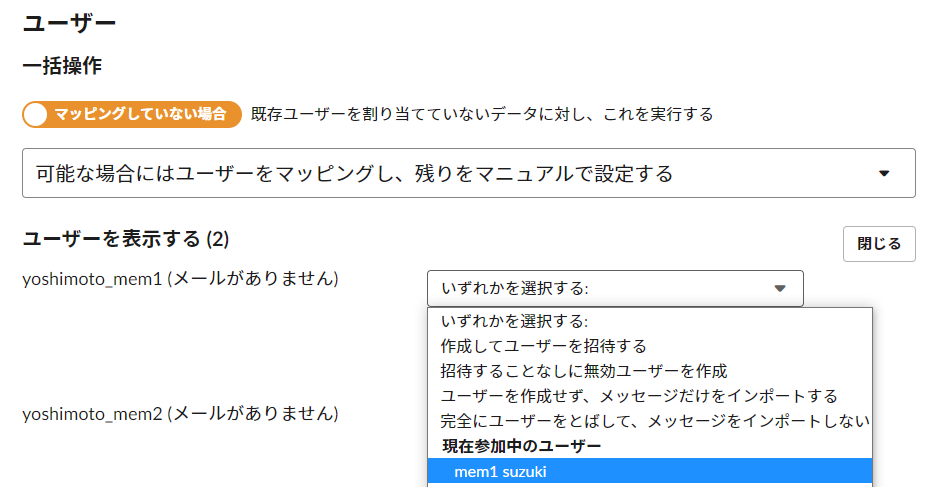
この画像は、Slackの仕様通りにCSVファイルにusernameを書いたが、自動マッピングがされなかったので、手動で既存のユーザーをプルダウンで選ぼうとしているところである。「可能な場合にはユーザーをマッピングし、残りをマニュアルで設定する」という選択肢があるのは、何らかの開発途中の機能か、ZIPファイルでのインポートとの整合性を取るためだったか、とにかく、可能な場合というのはないので、一つ一つ手動でマッピングするしかない。
なお、displaynameに同姓同名がいる場合、プルダウンから区別することはできない。ただし、ソースには value=としてユーザーIDが書いてあるので、デベロッパーツール(開発者ツール)で識別することは可能。以下は、mem1 suzukiさんが5人いたときの例。
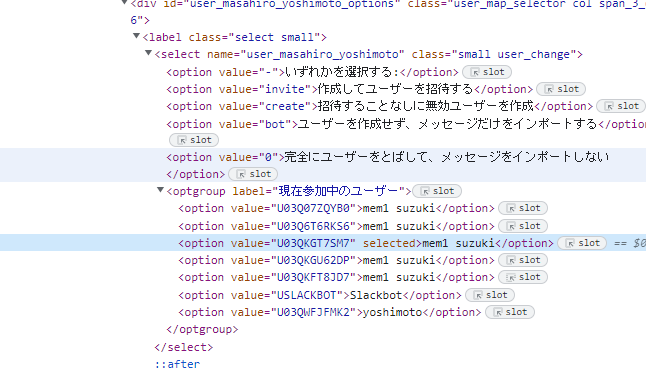
注1: 自動でマッピングさせたいなと思って、ユーザー名のところを、Slackで使われる username, fullname, displayname, userid, メールアドレスにしてみたが、どれも自動マッピングされなかった。Slackへの問い合わせで確定。
チャンネルのマッピング
パブリックチャンネルの場合
新WSに存在する既存のチャンネルに投稿を追加することができる。新しいチャンネルを自動で作ることも出来る。
プライベートチャンネルの場合
新WSの既存のプライベートチャンネルに投稿を追加することはできない。インポートすると、新しいプライベートチャンネルが自動作成され、そのメンバーはインポートの作業を行った管理者だけとなる。前述のユーザーのマッピングを行った場合でも、その他のユーザーはプライベートチャンネルに自動で招待されない。
インポート作業を、プライベートチャンネルに所属すべきメンバー以外の管理者が行う場合は、管理者によるインポート作業後、所属すべきメンバーのうち少なくとも一人をプライベートチャンネルに追加してもらい、その後管理者をチャンネルから外し、所属すべきメンバーを招待するという作業をしなければならない。
インポートしようとしたプライベートチャンネル名と同じチャンネルが既に存在した場合、チャンネル2 などと末尾に2が加えられた新プライベートチャンネルが自動作成される。チャンネル名は後で変更できるので、適切に運用すればよいだろう。
投稿時間 unixtime について
CSVファイルの最初の列のunixtime (Slack上ではタイムスタンプ=timestamp=TS)には小数が使える。最初の行のunixtimeで昇順ソートされていなければならない。同じCSVファイル内では同じunixtimeが使える。ただし、投稿のタイムスタンプはSlack側で勝手にずらし、異なる時間に投稿したことになる。
パブリックチャンネルに投稿をインポートした後、同じunixtimeの投稿を同じパブリックチャンネルにインポートすることはできない。した場合、「2 件のメッセージ と 0 個のファイルがインポートされました。」などと成功した感じのメッセージが出るが、実際はインポートされず、上書きもされない。既存のプライベートチャンネルへのインポートはできないので、この問題が起こるのはパブリックチャンネルだけである。
その他のtips
ユーザーを大量に手動マッピングしたくない場合や、新WSに存在しないユーザーがいる場合は、Botの投稿としてインポートすることもできる。全ての投稿をボットにするときは「ユーザーを作成せず、メッセージはボットメッセージとして残す」を選べば良い。その場合、ユーザー名はCSVに書いた通りになり、下記の画像のようにユーザー名の横に「アプリ」と表記される。
スレッド構造、ファイル、リアクションはCSVファイルでは移行できない。
対ユーザーの@投稿、@ユーザー名 は利用可能。 <@新WSのuserid>とすれば、新WSのdisplaynameに置き換わる。
CSVファイルの文字コードはUTF-8
1作業に限りロールバックできる。インポートした後で、想定した挙動をしなかったら、ロールバックすればよい。最初は、捨てWSを作って、挙動を確認することをお勧めする。
CSVファイルによるインポートでフリープラン90日問題の影響を回避できるわけではない。本件の新WSはエンタープライズ(有料版)のSlackで運用されており、フリープラン90日問題の影響は受けない。ただし、CSVファイルでのインポートを使うと投稿日時を自在にずらすことができる。インポートによる投稿日時が90日ルールでどう判定されるかは分からない。過去の投稿を新しいタイムスタンプで再インポートし続けるという手もあるが、実用上うまくいくとは思えない。
インポートしたチャンネルでは、投稿の間にある 日付等 の右のvをクリックすると出てくる「今日、機能、先週、先月」には正しく反応するが、「最初」は最初ではなくインポート時点に飛ばされる。「カレンダーを使った移動」は、実際の投稿日である過去の日付、つまりインポートした日より前を選ぶことができない。→Slackに問い合わせた結果、2022/07/22時点では、
いただいた内容をもとに確認したところ、ご指摘のとおり「特定の日付に移動」についてはインポート以前の日付には機能しないことがわかりました。
この仕様が理想的な動作でないことはチーム一同認識しており、今後の動作改善を検討しています。
とのこと。回避策として検索機能を使って探すことを勧められた。カレンダー機能を頻繁に使っている場合は留意。